Scrapy is one of the most accessible tools that you can use to scrape and also spider a website with effortless ease.
One of the significant issues with Web crawlers is the fact that they break so easily. Using a framework like Scrapy and using the Contracts module to check the return data is one of the best ways to write crawlers you can trust.
First, let's write a simple scraper and then see how we can use Contracts to see that nothing is broken because you changed your code.
Our Simple Scraper
Today lets see how we can scrape Amazon to get reviews for lets, to say the Apple Air pods.
Here is the URL we are going to scrape https://www.amazon.com/Apple-AirPods-Charging-Latest-Model/dp/B07PXGQC1Q?pf_rd_p=35490539-d10f-5014-aa29-827668c75392&pf_rd_r=6T723HNZTK1TCR53MSAG&pd_rd_wg=U5S97&ref_=pd_gw_ri&pd_rd_w=rFFcu&pd_rd_r=9ea5f81c-8328-4375-bf2c-874e4f045991#customerReviews
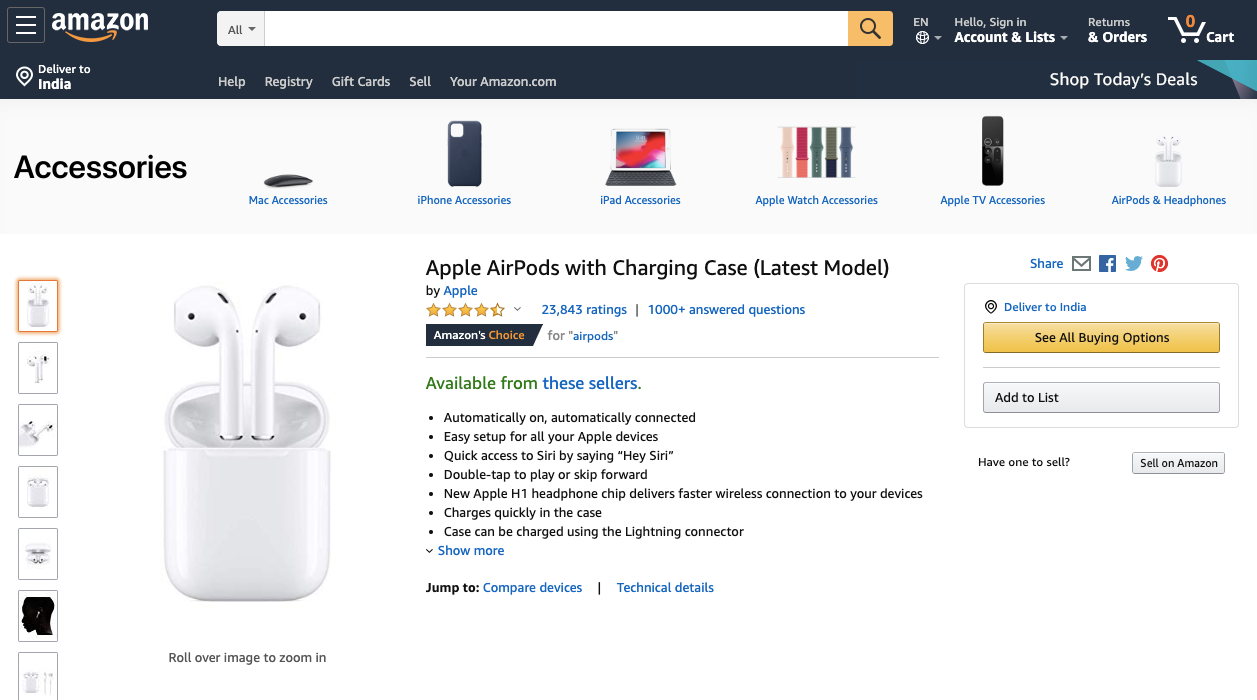
Especially the review area.
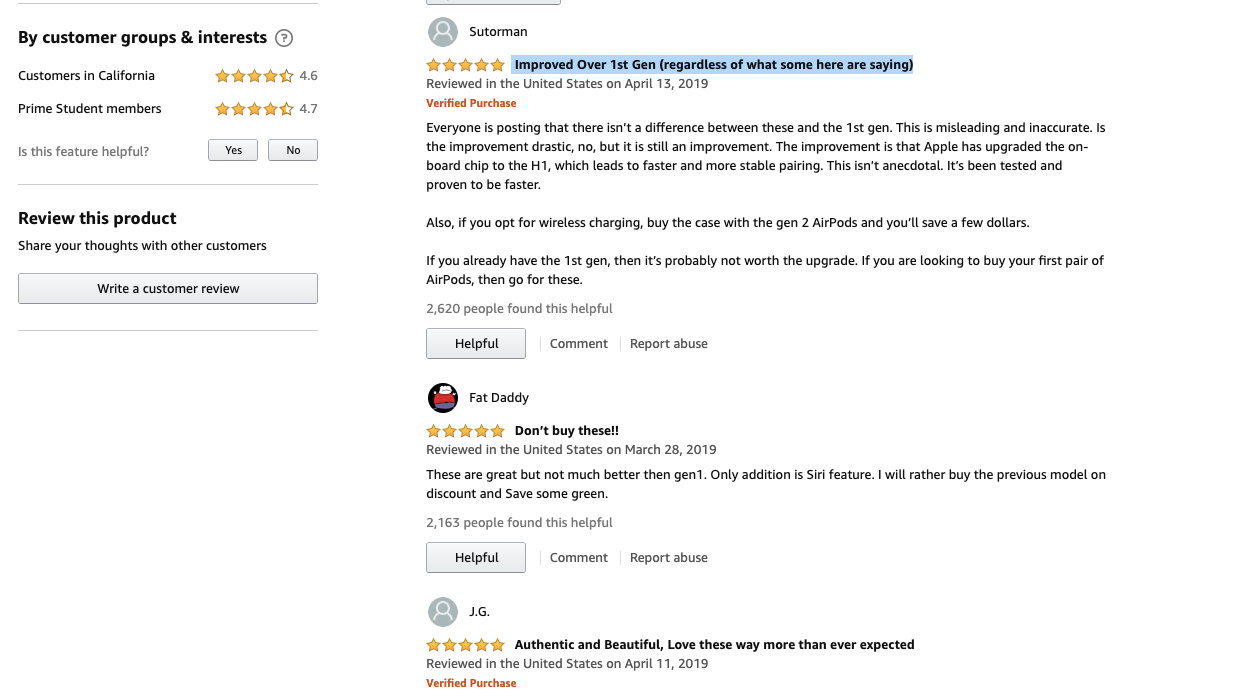
First, we need to install scrapy if you haven't already.
pip install scrapy
Once installed, go ahead and create a project by invoking the startproject command.
scrapy startproject scrapingproject
This will output something like this.
New Scrapy project 'scrapingproject', using template directory '/Library/Python/2.7/site-packages/scrapy/templates/project', created in:
/Applications/MAMP/htdocs/scrapy_examples/scrapingproject
You can start your first spider with:
cd scrapingproject
scrapy genspider example example.com
And create a folder structure like this.
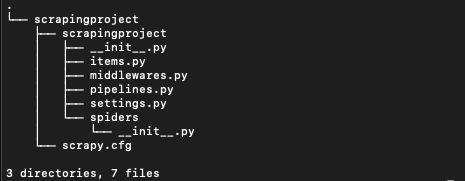
Now CD into the scrapingproject. You will need to do it twice like this.
cd scrapingproject
cd scrapingproject
Now we need a spider to crawl through the Amazon reviews page. So we use the genspider to tell scrapy to create one for us. We call the spider ourfirstbot and pass it to the URL of the Amazon page.
scrapy genspider ourfirstbot https://www.amazon.com/Apple-AirPods-Charging-Latest-Model/dp/B07PXGQC1Q?pf_rd_p=35490539-d10f-5014-aa29-827668c75392&pf_rd_r=6T723HNZTK1TCR53MSAG&pd_rd_wg=U5S97&ref_=pd_gw_ri&pd_rd_w=rFFcu&pd_rd_r=9ea5f81c-8328-4375-bf2c-874e4f045991#customerReviewsThis should return successfully like this.
Created spider 'ourfirstbot' using template 'basic' in module:
scrapingproject.spiders.ourfirstbot
Great. Now open the file ourfirstbot.py in the spider's folder. It should look like this.
# -*- coding: utf-8 -*-
import scrapy
class OurfirstbotSpider(scrapy.Spider):
name = 'ourfirstbot'
start_urls = ['https://www.amazon.com/Apple-AirPods-Charging-Latest-Model/dp/B07PXGQC1Q?pf_rd_p=35490539-d10f-5014-aa29-827668c75392&pf_rd_r=6T723HNZTK1TCR53MSAG&pd_rd_wg=U5S97&ref_=pd_gw_ri&pd_rd_w=rFFcu&pd_rd_r=9ea5f81c-8328-4375-bf2c-874e4f045991#customerReviews']
def parse(self, response):
passLet's examine this code before we proceed.
The allowed_domains array restricts all further crawling to the domain paths specified here.
start_urls is the list of URLs to crawl. For us, in this example, we only need one URL.
The def parse(self, response): function is called by scrapy after every successful URL crawl. Here is where we can write our code to extract the data we want.
We now need to find the CSS selector of the elements we need to extract the data. Go to the URL https://www.amazon.com/Apple-AirPods-Charging-Latest-Model/dp/B07PXGQC1Q?pf_rd_p=35490539-d10f-5014-aa29-827668c75392&pf_rd_r=6T723HNZTK1TCR53MSAG&pd_rd_wg=U5S97&ref_=pd_gw_ri&pd_rd_w=rFFcu&pd_rd_r=9ea5f81c-8328-4375-bf2c-874e4f045991#customerReviews
And right-click on the title of one of the reviews and click on inspect. This will open the Google Chrome Inspector like below.
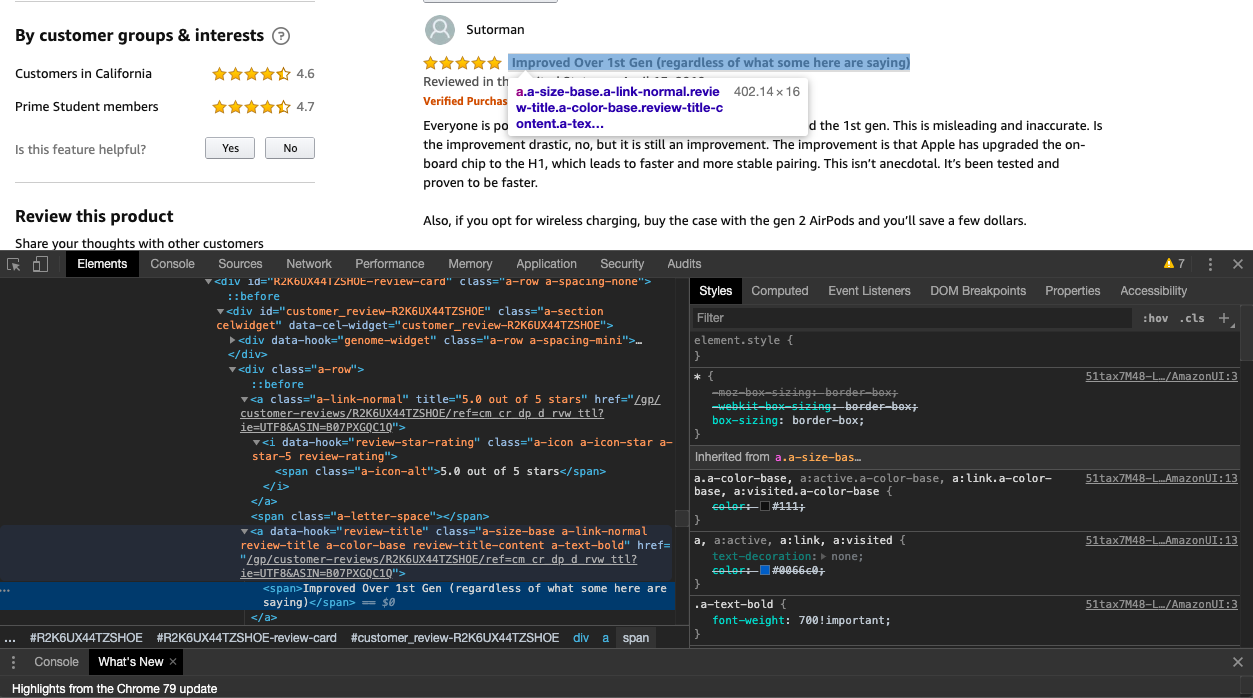
You can see that the CSS class name of the title element is review-title, so we are going to ask scrapy to get us the contents of this class like this.
names = response.css('.review-title').extract()Similarly, we try and find the class names of the review rating element (note that the class names might change by the time you run this code)
reviews = response.css('.review-rating').extract()If you are unfamiliar with CSS selectors, you can refer to this page by Scrapy https://docs.scrapy.org/en/latest/topics/selectors.html
We have to use the zip function now to map a similar index of multiple containers so that they can be used just using a single entity. So here is how it looks.
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
class OurfirstbotSpider(scrapy.Spider):
name = 'ourfirstbot'
start_urls = [
'https://www.amazon.com/Apple-AirPods-Charging-Latest-Model/dp/B07PXGQC1Q?pf_rd_p=35490539-d10f-5014-aa29-827668c75392&pf_rd_r=6T723HNZTK1TCR53MSAG&pd_rd_wg=U5S97&ref_=pd_gw_ri&pd_rd_w=rFFcu&pd_rd_r=9ea5f81c-8328-4375-bf2c-874e4f045991#customerReviews',
]
def parse(self, response):
#yield response
title = response.css('.review-title').extract()
reviews = response.css('.review-rating').extract()
#Give the extracted content row wise
for item in zip(title, reviews):
#create a dictionary to store the scraped info
all_items = {
'title' : BeautifulSoup(item[0]).text,
'reviews' : BeautifulSoup(item[1]).text,
}
#yield or give the scraped info to scrapy
yield all_items
We use BeautifulSoup to remove HTML tags and get pure text
and now lets run this with the command (Notice we are turning off obeying Robots.txt)
scrapy crawl ourfirstbot -s ROBOTSTXT_OBEY=FalseAnd Bingo. you get the results as below.

Now, let's export the extracted data to a CSV file. All you have to do is to provide an export file like this.
scrapy crawl ourfirstbot -o data.csvOr if you want the data in the JSON format.
scrapy crawl ourfirstbot -o data.json
Using Contracts to detect code breakages
As we know, the parse function needs to return the review title and review rating. Let's pretend this is super important and sacrosanct for our process. To make sure that in a lengthier implementation, the basics are not broken, we specify using the multi-line docstrings. The contract "syntax" is: @contract_name . You can create your own contracts, which is pretty neat.
def parse(self, response):
"""This function gathers the author and the quote text.
@url https://www.amazon.com
@scrapes title reviews
@items 1 10
"""
This tells the Contracts module to check if the URL is the right one and the fields that need to be there definitely and the number of items minimum one and maximum ten that the count should fall under.
Let's modify the code to add the support of the Contracts module.
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
from scrapy.contracts import ContractsManager
from scrapy.contracts.default import (
UrlContract,
ReturnsContract,
ScrapesContract,
)
class blogCrawler(CrawlSpider):
name = 'ourfirstbot'
start_urls = [
'https://www.amazon.com/Apple-AirPods-Charging-Latest-Model/dp/B07PXGQC1Q?pf_rd_p=35490539-d10f-5014-aa29-827668c75392&pf_rd_r=6T723HNZTK1TCR53MSAG&pd_rd_wg=U5S97&ref_=pd_gw_ri&pd_rd_w=rFFcu&pd_rd_r=9ea5f81c-8328-4375-bf2c-874e4f045991#customerReviews',
]
def parse(self, response):
"""This function gathers the author and the quote text.
@url https://www.amazon.com
@scrapes title reviews
@items 1 10
"""
title = response.css('.review-title').extract()
reviews = response.css('.review-rating').extract()
#Give the extracted content row wise
for item in zip(title, reviews):
#create a dictionary to store the scraped info
all_items = {
'title' : BeautifulSoup(item[0]).text,
'reviews' : BeautifulSoup(item[1]).text,
}
#yield or give the scraped info to scrapy
yield all_itemsNow when you change some part of the code, you can check for the integrity of code by running.
scrapy checkWhich should return the following if all went well.
...
----------------------------------------------------------------------
Ran 3 contracts in 0.120s
OKIf you really want to build trustworthy web crawlers, you can consider using a Rotating Proxy Service like Proxies API which prevents IP blocks or looks at a cloud-based web crawler which can handle all these subtleties behind the scenes like TeraCrawler.io