This code scrapes Airbnb listings and prints them out.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.airbnb.co.in/s/New-York--NY--United-States/homes?query=New York, NY, United States&checkin=2020-03-12&checkout=2020-03-19&adults=4&children=1&infants=0&guests=5&place_id=ChIJOwg_06VPwokRYv534QaPC8g&refinement_paths[]=/for_you&toddlers=0&source=mc_search_bar&search_type=unknown'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('[itemprop=itemListElement]'):
try:
print('----------------------------------------')
print(item.select('a')[0]['aria-label'])
print(item.select('a')[0]['href'])
print(item.select('._krjbj')[0].get_text())
print(item.select('._krjbj')[1].get_text())
print(item.select('._16shi2n')[0].get_text())
print(item.select('._zkkcbwd')[0].get_text())
print(name)
print('----------------------------------------')
except Exception as e:
#raise e
print('')
When you save it as scrapeAirbnb.py and run it, it will get your the details.
python3 scrapeAirbnb.py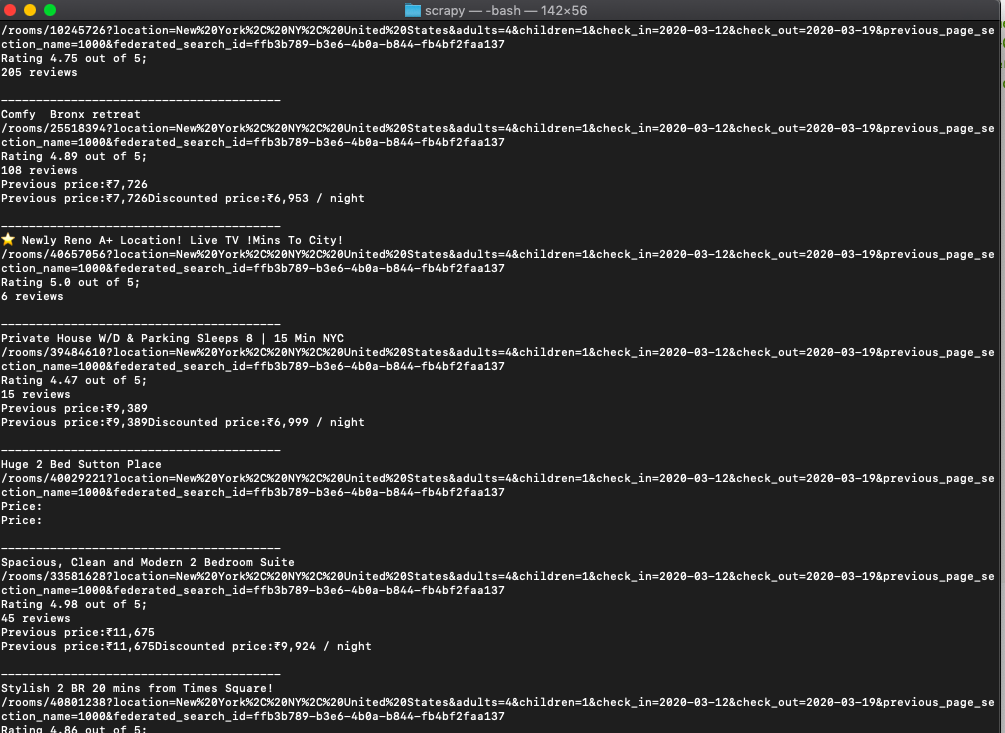
So is the job done? Finito?
Far from it. If this needs to go into production, at any decent level of scale, you will need all sorts of mechanisms to make sure this can function without breaking.
- You will need to handle website timeouts
- You will probably need to download images
- You will need to pretend to be a web browser very well using User-Agent strings and other techniques
- You will need to rotate user-agent strings
- You will need to read the Robots.txt and respect it
- You will need to send asynchronous requests if you have a lot of URLs to scrape
- You may need distributed servers to handle the load if this has multiple domains to be crawled all asynchronously
- You will need monitoring, tracking, and alerting mechanism for when the crawler breaks for any reason.
- You will need to handle the incoming data at large quantities, detect the finish of a job, send out alerts, and make data available for download or further consumption in various formats like XML, CSV, or JSON.
- You may need to handle cookies that the web server sends.
- You will need to handle CAPTCHAs and other restrictions that the website will impose after crawling a few hundred URLs
- You will need to handle total IP Bans.
The list goes on. Web crawling is amazingly complex, frustrating even in the beginning.
It can be extremely rewarding once you have established a reliable, schedulable, and manageable crawler/scraper setup that has all of the things above finally in place.
Use this as a checklist in your future web crawling projects and comment below if you have other items to add to this.
If you want a cloud-based crawling software that can do all of that and more behind the scenes in a reliable fashion, you can consider using our product TeraCrawler.io for crawling large sets of URLs. For overcoming IP bans, I recommend using our other product Proxies API, which is a rotating proxies API that can route your requests through a pool of over 2 million IPs making IP bans almost impossible.