Today we are going to see how we can scrape Flipkart data using Python and BeautifulSoup in a simple and elegant manner.
The aim of this article is to get you started on a real-world problem solving while keeping it super simple so you get familiar and get practical results as fast as possible.
So the first thing we need is to make sure we have Python 3 installed. If not, you can just get Python 3 and get it installed before you proceed.
Then you can install beautiful soup with:
pip3 install beautifulsoup4We will also need the libraries requests, lxml, and soupsieve to fetch data, break it down to XML, and to use CSS selectors. Install them using...
pip3 install requests soupsieve lxmlOnce installed open an editor and type in:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsNow let's go to the Flipkart listing page and inspect the data we can get.
This is how it looks:
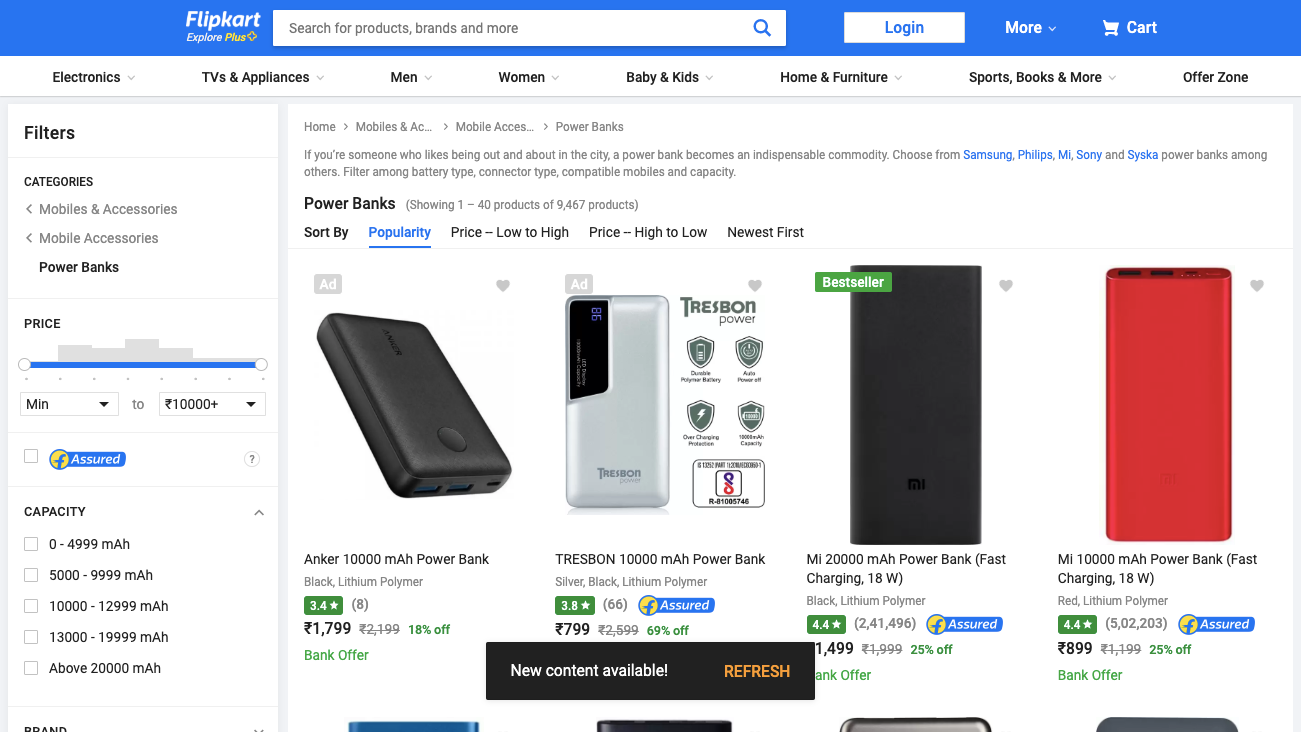
Back to our code now. Let's try and get this data by pretending we are a browser like this:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.flipkart.com/mobile-accessories/power-banks/pr?sid=tyy,4mr,fu6&otracker=categorytree&otracker=nmenu_sub_Electronics_0_Power Banks'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')Save this as scrapeFlipkart.py.
If you run it:
python3 scrapeFlipkart.pyYou will see the whole HTML page.
Now, let's use CSS selectors to get to the data we want. To do that let's go back to Chrome and open the inspect tool.
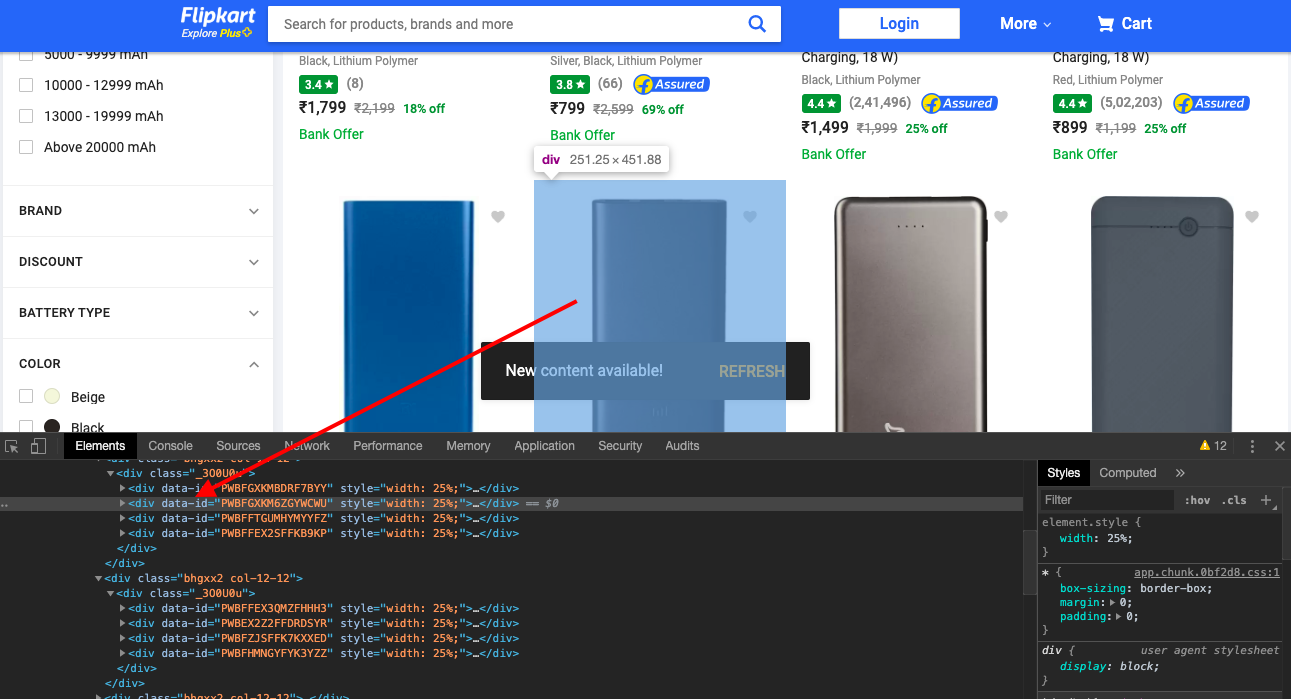
We notice that all the individual product data are contained in a with the attribute data-id. You also notice that the attribute value is some gibberish and it's always changing. We cant use this. But the clue is the presence of the data-id attribute itself. That's all we need. So let's extract that.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.flipkart.com/mobile-accessories/power-banks/pr?sid=tyy,4mr,fu6&otracker=categorytree&otracker=nmenu_sub_Electronics_0_Power Banks'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('[data-id]'):
try:
print('----------------------------------------')
print(item)
except Exception as e:
#raise e
b=0This prints all the content in each of the containers that hold the product data.
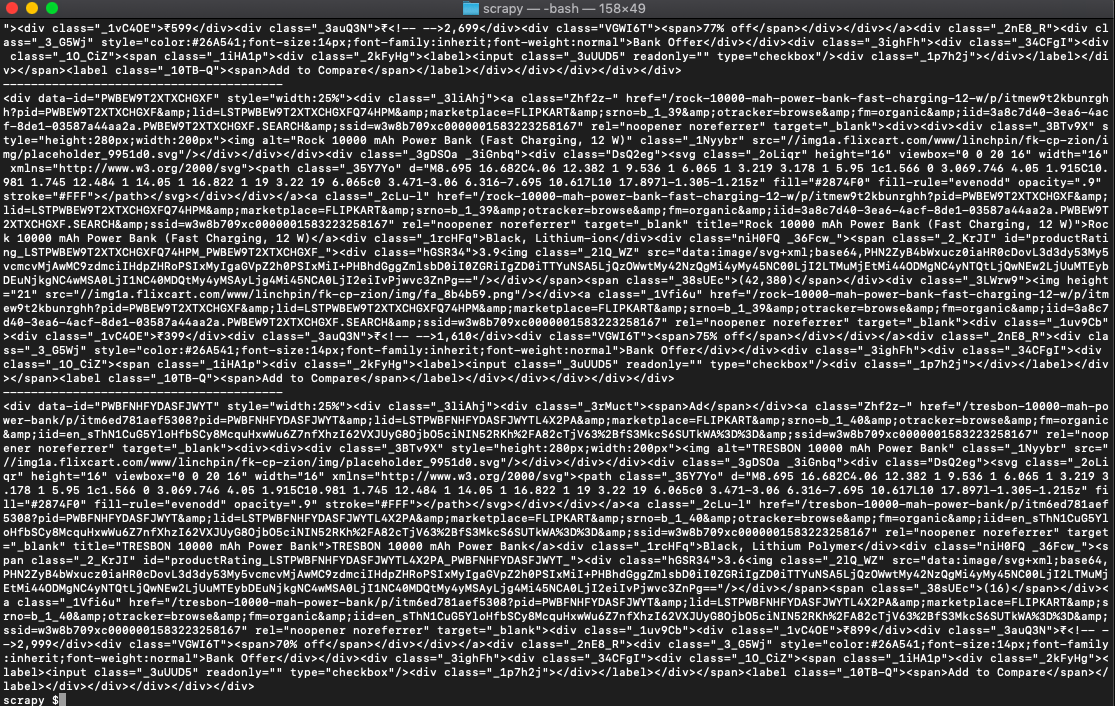
We now get to work for each of the fields we want. This is challenging because Flipkart HTML has no meaningful CSS classes we can use. So we will resort to some tricks that could be reliable.
For the title we notice that the first anchor tag has an image inside it which always has the title in its alt attribute. So let's get that.
print(item.select('a img')[0]['alt'])
print(item.select('a')[0]['href'])The second line above gives us the URL to the listing.
The product rating has a meaningful id productRating followed by some gibberish. But we can use the *= operator to select anything which has the word productRating like this:
print(item.select('[id*=productRating]')[0].get_text().strip())Scraping the price is even more challenging because it has no discernable class name or ID as a clue to get to it. But it always has the currency denominator ₹ in it. So we use regex to find it.
prices = item.find_all(text=re.compile('₹'))
print(prices[0])We do the same to get the discount percentage. It always has the word off in it.
discounts = item.find_all(text=re.compile('off'))
print(discounts[0])Putting it all together.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.flipkart.com/mobile-accessories/power-banks/pr?sid=tyy,4mr,fu6&otracker=categorytree&otracker=nmenu_sub_Electronics_0_Power Banks'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('[data-id]'):
try:
print('----------------------------------------')
#print(item)
print(item.select('a img')[0]['alt'])
print(item.select('a')[0]['href'])
print(item.select('[id*=productRating]')[0].get_text().strip())
prices = item.find_all(text=re.compile('₹'))
print(prices[0])
discounts = item.find_all(text=re.compile('off'))
print(discounts[0])
except Exception as e:
#raise e
b=0If you run it it will print out all the details.
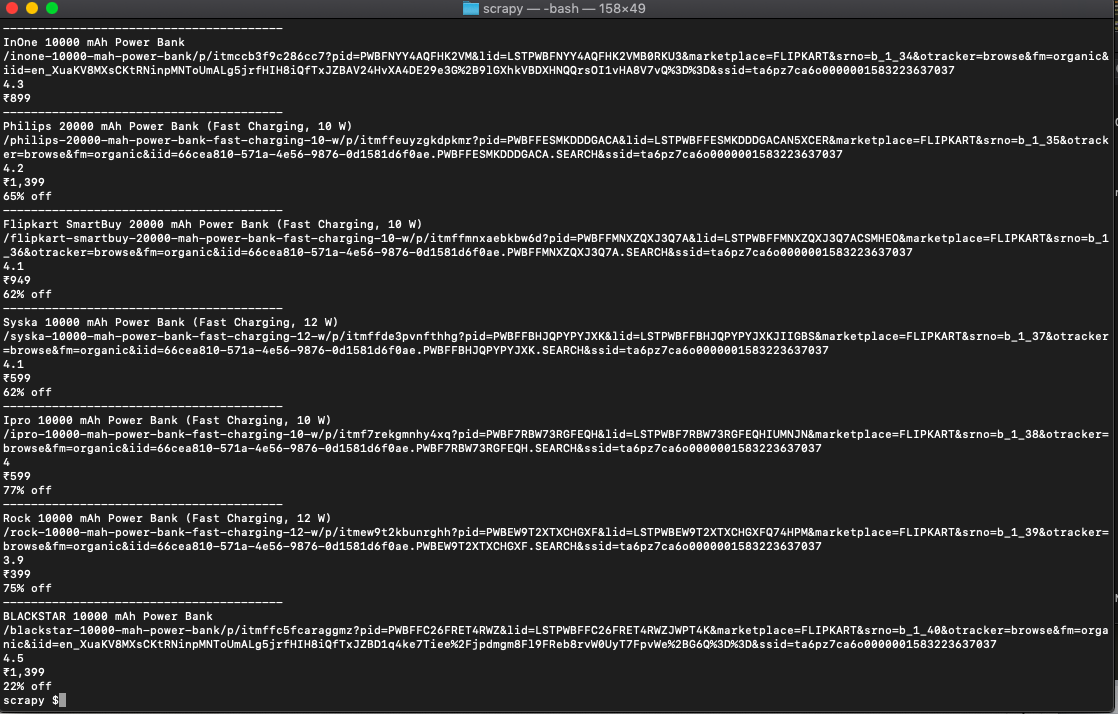
Bingo!! we got them all. That was challenging and satisfying.
If you want to use this in production and want to scale to thousands of links then you will find that you will get IP blocked easily by Flipkart. In this scenario using a rotating proxy service to rotate IPs is almost a must. You can use a service like Proxies API to route your calls through a pool of millions of residential proxies.
If you want to scale the crawling speed and dont want to set up your own infrastructure, you can use our Cloud base crawler crawltohell.com to easily crawl thousands of URLs at high speed from our network of crawlers.