Today we are going to see how we can scrape Corona Virus data using Python and BeautifulSoup in a simple manner.
The aim of this article is to get you started on a real-world problem solving while keeping it super simple so you get familiar and get practical results as fast as possible.
So the first thing we need is to make sure we have Python 3 installed. If not, you can just get Python 3 and get it installed before you proceed.
Then you can install beautiful soup with:
pip3 install beautifulsoup4We will also need the libraries requests, lxml, and soupsieve to fetch data, break it down to XML, and to use CSS selectors. Install them using:
pip3 install requests soupsieve lxmlOnce installed open an editor and type in:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsNow let's go to the Corona Virus data listing page at the ECDC website and inspect the data we can get.
This is how it looks:
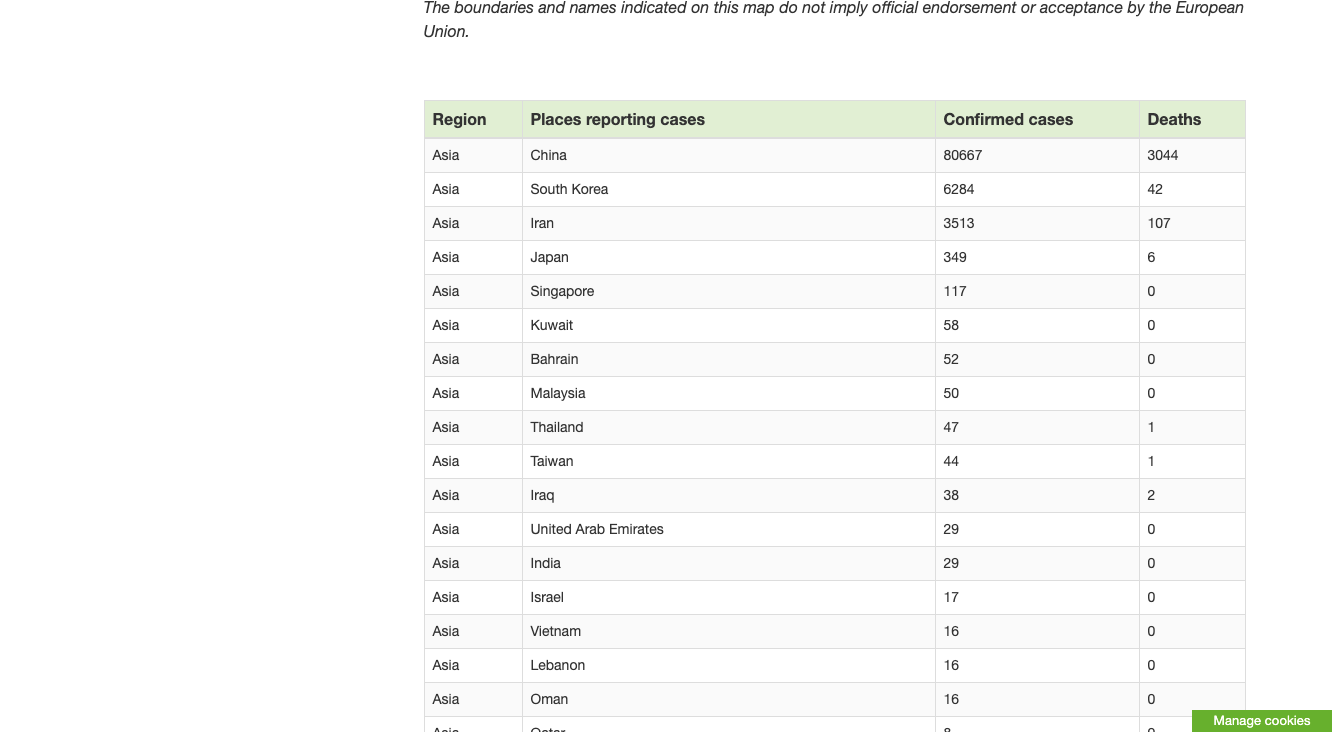
Back to our code now. Let's try and get this data by pretending we are a browser like this:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')Save this as scrapeCorona.py.
If you run it.
python3 scrapeCorona.pyYou will see the whole HTML page
Now, let's use CSS selectors to get to the data we want. To do that let's go back to Chrome and open the inspect tool.
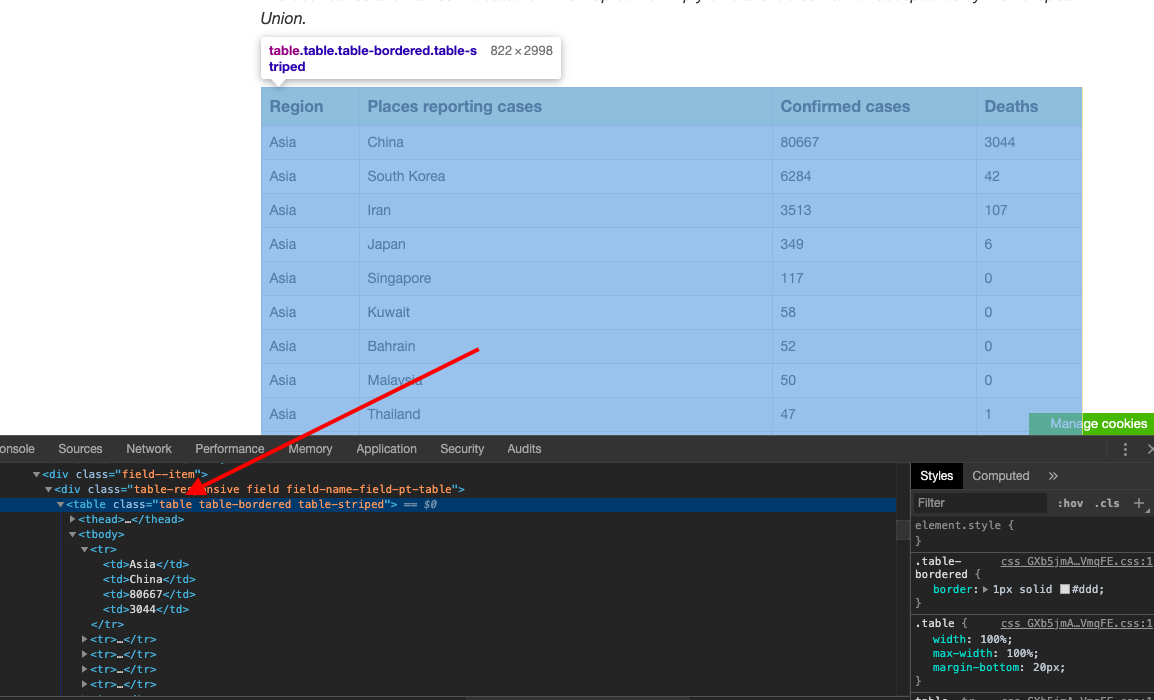
We notice that all the individual product data are contained in a with rows containing individual country info and the tags containing the specific fields of data.
So we can extract them like this:
If we run it we will get all the data we need. 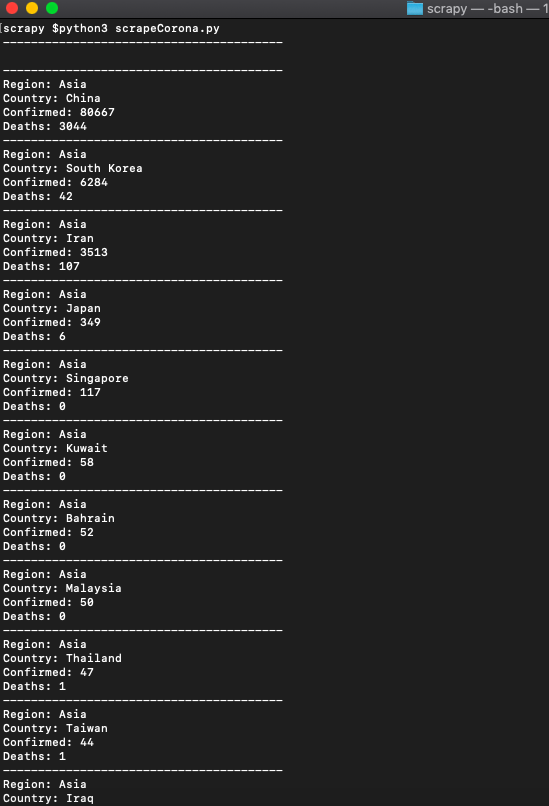 We got them all.
If you want to use this in production and want to scale to thousands of links then you will find that you will get IP blocked easily by several websites. In this scenario using a rotating proxy service to rotate IPs is almost a must. You can use a service like Proxies API to route your calls through a pool of millions of residential proxies. If you want to scale the crawling speed and dont want to set up your own infrastructure, you can use our Cloud base crawler crawltohell.com to easily crawl thousands of URLs at high speed from our network of crawlers. |