Web scraping is one of the best ways to generate leads for your business quite easily.
Today we will look at a practical example of how to get leads from online business directories.
Here are 57 of them that you can scrape leads from
List of Online Directories
That's a lot. So in this article lets learn how to scrape one of them, Yellow pages so that you can use the same techniques to scrape data from the others. Here we are imagining a scenario where we are looking to generate a list of Dentists that we can target.
BeautifulSoup will help us extract information, and we will retrieve crucial pieces of information from Yellow Pages.
To start with, this is the boilerplate code we need to get the Yellowpages.com search results page and set up BeautifulSoup to help us use CSS selectors to query the page for meaningful data.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.yellowpages.com/los-angeles-ca/dentists'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')We are also passing the user agent headers to simulate a browser call, so we dont get blocked.
Now let's analyse the Yellow pages search results. This is how it looks.
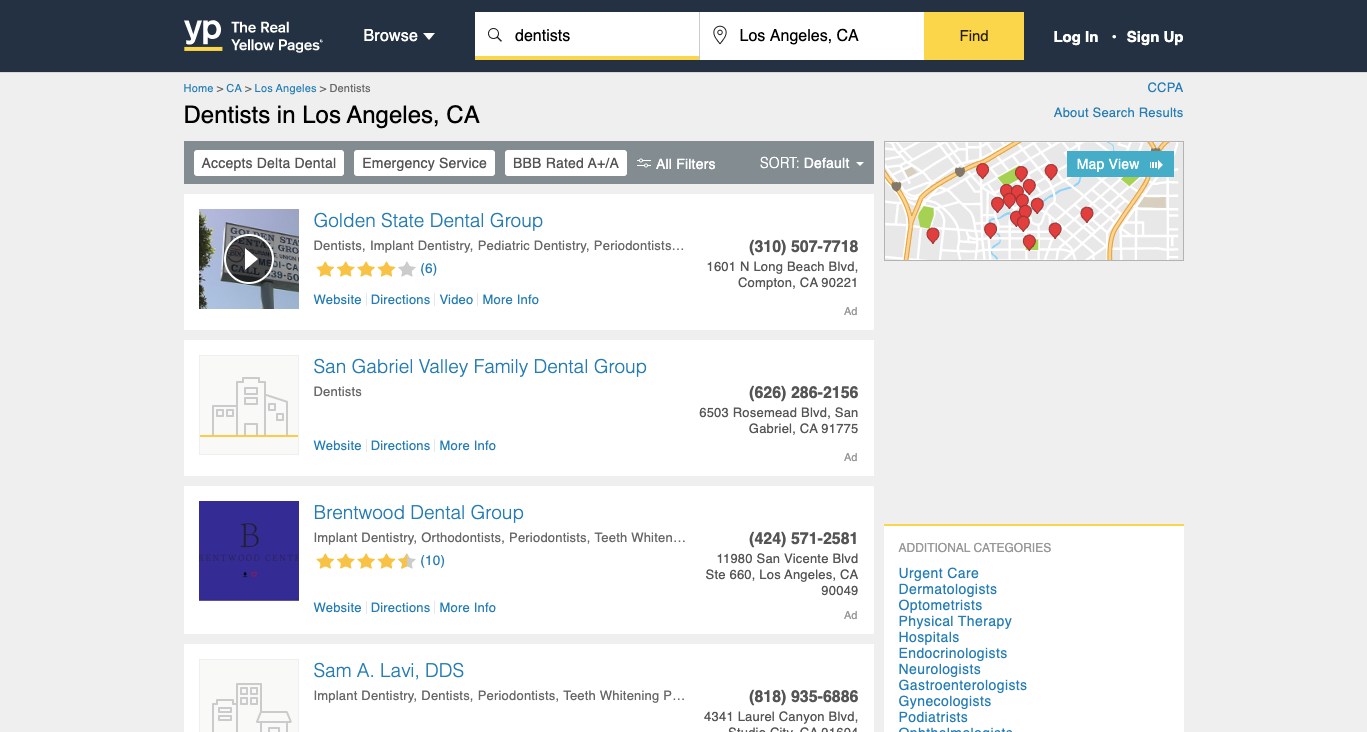
And when we inspect the page, we find that each of the items HTML is encapsulated in a tag with the class v-card
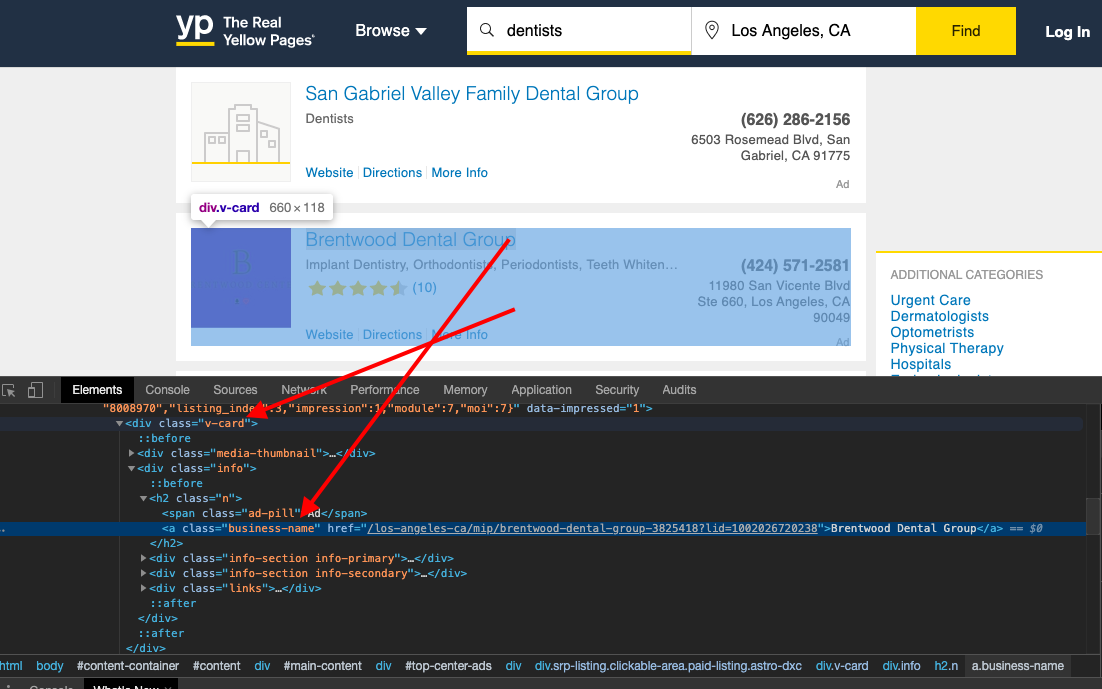
We could just use this to break the HTML document into these cards which contain individual item information like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.yellowpages.com/los-angeles-ca/dentists'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.v-card'):
try:
print('----------------------------------------')
print(item)And when you run it.
python3 scrapeYellow.pyYou can tell that the code is isolating the v-cards HTML
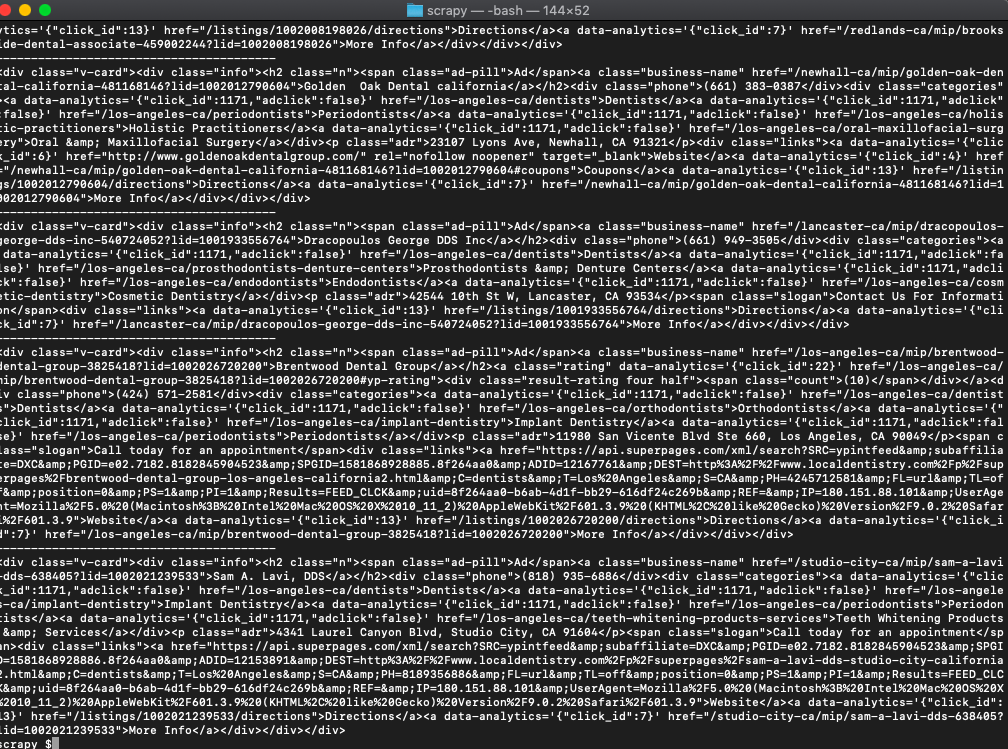
On further inspection, you can see that the name of the place always has the class business-name. So let's try and retrieve that.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.yellowpages.com/los-angeles-ca/dentists'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.v-card'):
try:
print('----------------------------------------')
print(item.select('.business-name')[0].get_text())
except Exception as e:
#raise e
print('')That will get us the names.
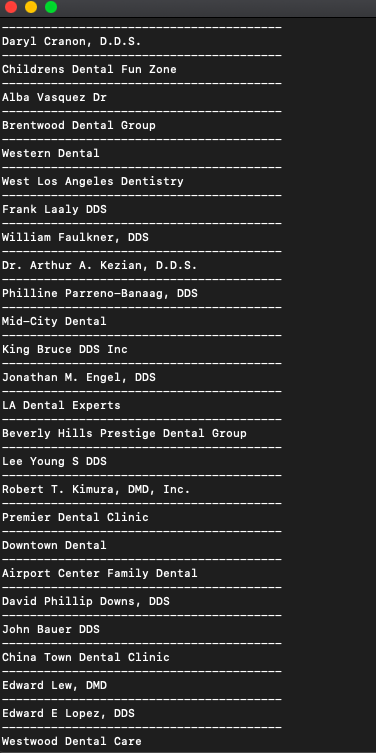
Bingo!
Now let's get the other data pieces.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.yellowpages.com/los-angeles-ca/dentists'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.v-card'):
try:
print('----------------------------------------')
print(item.select('.business-name')[0].get_text())
print(item.select('.rating div')[0]['class'])
print(item.select('.rating div span')[0].get_text())
print(item.select('.phone')[0].get_text())
print(item.select('.adr')[0].get_text())
#print(item.select('.business-name')[0].get_text())
print('----------------------------------------')
except Exception as e:
#raise e
print('')
And when run.
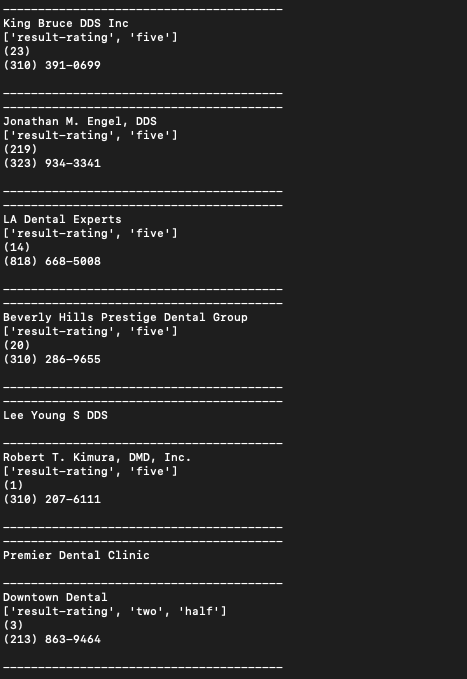
Produces all the info we need including ratings, reviews, phone, address etc
If you want to use this in production and want to scale to thousands of links, then you will find that you will get IP blocked easily by Yellow Pages. In this scenario, using a rotating proxy service to rotate IPs is almost a must. You can use a service like Proxies API to route your calls through a pool of millions of residential proxies.
If you want to scale the crawling speed and dont want to set up you own infrastructure, you can use our Cloud base crawler crawltohell.com to easily crawl thousands of URLs at high speed from our network of crawlers.