Today we are going to see how we can scrape business data from NCA Business Directory using Python and BeautifulSoup is a simple and elegant manner.
This article aims to get you started on a real-world problem solving while keeping it super simple, so you get familiar and get practical results as fast as possible.
So the first thing we need is to make sure we have Python 3 installed. If not, you can just get Python 3 and get it installed before you proceed.
Then you can install beautiful soup with
pip3 install beautifulsoup4
We will also need the libraries requests, lxml and soupsieve to fetch data, break it down to XML and to use CSS selectors. Install them using.
pip3 install requests soupsieve lxml
Once installed, open an editor and type in.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsNow let's go to the Directory listing page and inspect the data we can get.
This is how it looks.
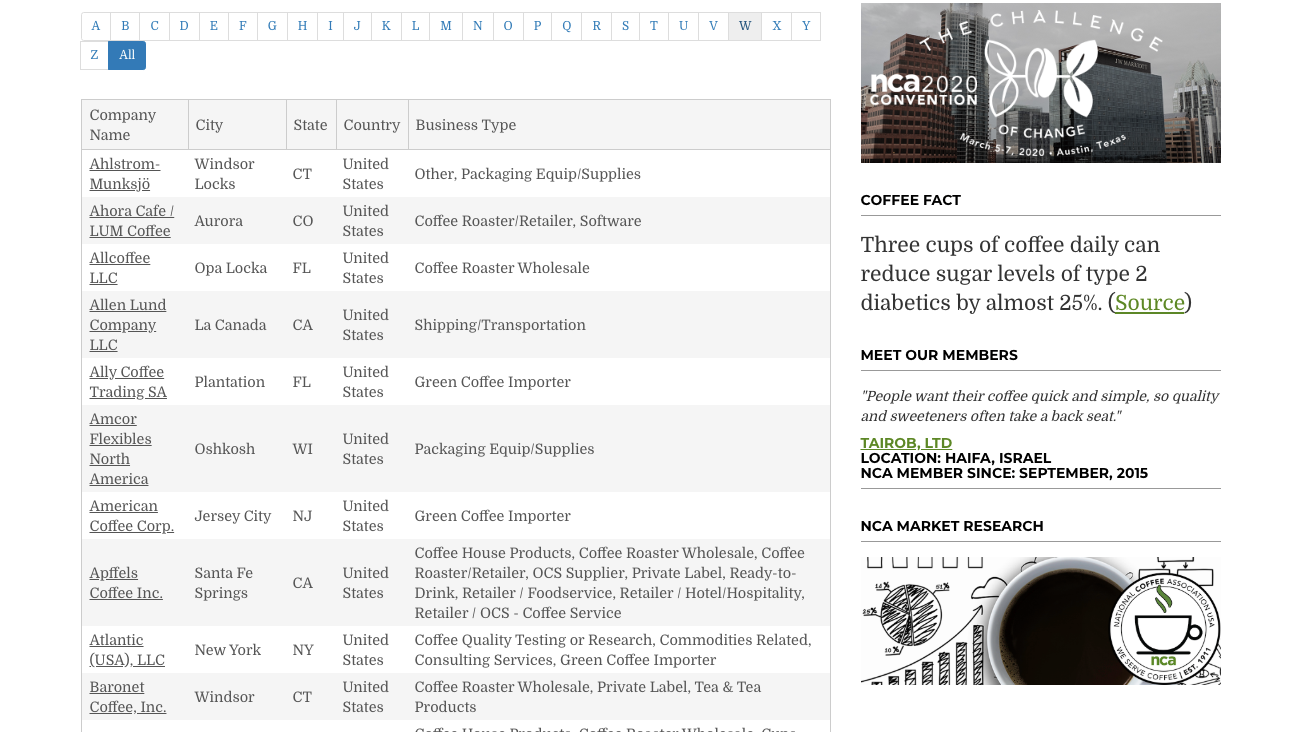
This page has the typical look of one that uses AJAX to load its data.
So we need to find how we can replicate an AJAX call.
Let's open the Chrome inspector tool and go to the networks tab. Now if we press the eht search button, we can see a network request (AJAX call) being made as shown in the pic below.
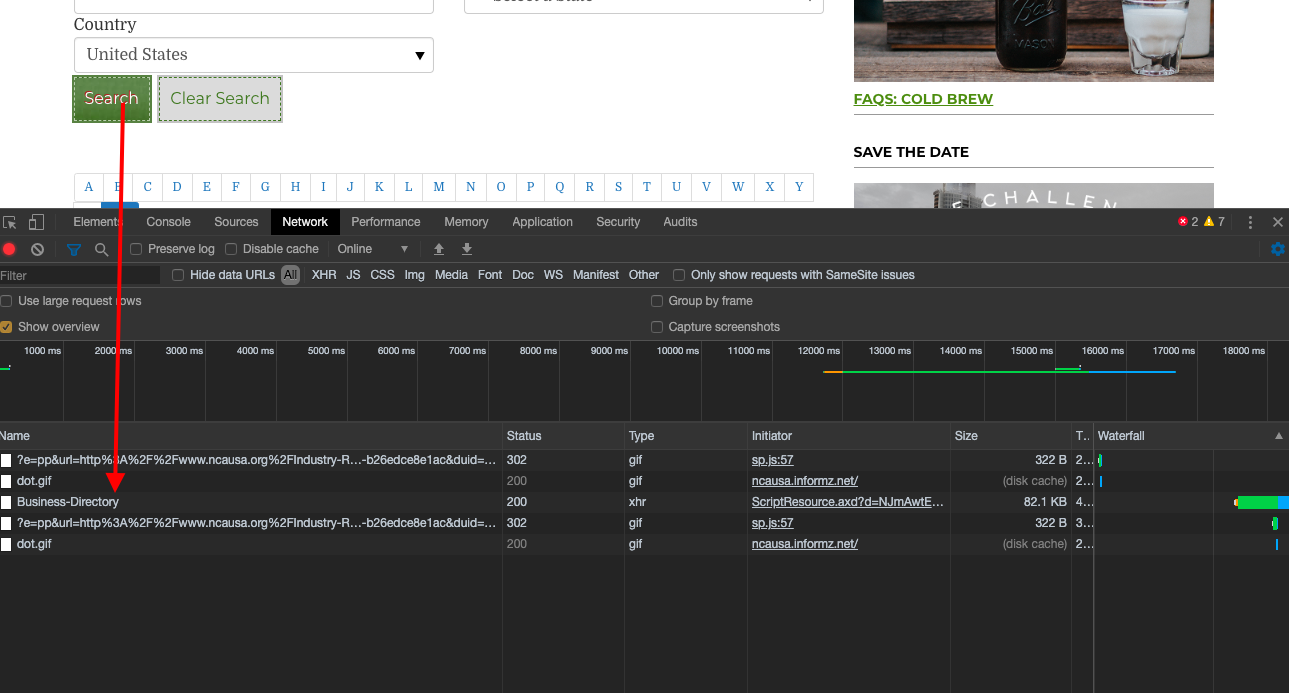
Let's dive deeper into this request.
You will see its a complicated POST call with all sorts of values. We have to use a trick to get them all pulled out of there.
You right-click on the original call and in the menu select copy → copy as cURL
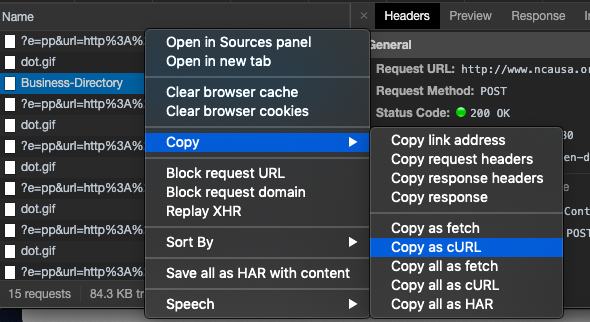
That will give use a curl request that will look like this.
curl 'http://www.ncausa.org/Industry-Resources/Business-Directory' -H 'Connection: keep-alive' -H 'Cache-Control: no-cache' -H 'X-Requested-With: XMLHttpRequest' -H 'X-MicrosoftAjax: Delta=true' -H 'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' -H 'Accept: */*' -H 'Origin: http://www.ncausa.org' -H 'Referer: http://www.ncausa.org/Industry-Resources/Business-Directory' -H 'Accept-Language: en-US,en;q=0.9' -H 'Cookie: dnn_IsMobile=False; language=en-US; .ASPXANONYMOUS=e0r2MG_3G6Dr7sytXHbwodyjh_3ZKWEqkz5WDWOqOFrehxApQE8OqZIuUhBopTrmKcTHwbQPYZFmgWoYRMbswjq2sN5A0hXE6gh8YCHsbx8ilWXD0; Analytics_VisitorId=a7bde630-6d79-4889-ad76-62d8b2f7a5c1; Analytics=SessionId=b11a4874-867d-4803-a157-2bfaca7e9ecd&TabId=3091&ContentItemId=-1; DotNetNukeAnonymous=d6769dec-89b3-4cc5-ab41-bea096e48bd0; ASP.NET_SessionId=fmfgelwzj3xit5bqbjpr4s1j; __RequestVerificationToken=3ZuvkI0J2CBSB4DRS6uDPoonuuX1CMvjin1agg6to6bagWIa8ihCEnqp7z5T1_FYjtdXNA2; _sp_ses.ca33=*; _&__VIEWSTATEENCRYPTED=&__ASYNCPOST=true&dnn$ctr5939$Clients_Custom$ctl00$btnSearch=Search' --compressed --insecure
Glad we didn't have to type that by hand.
When you open the terminal and issue the curl command, you can see that we get the results!
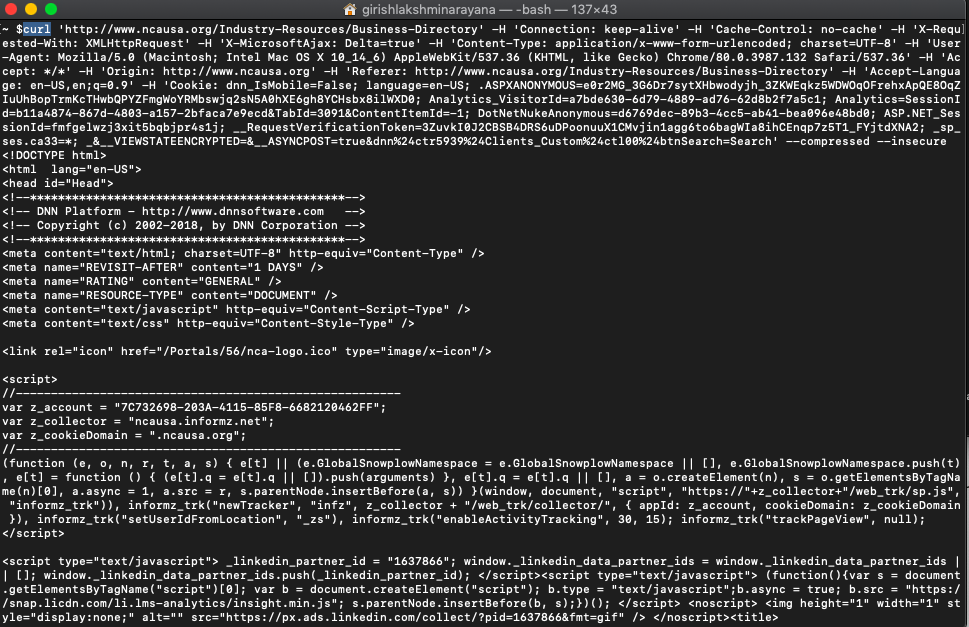
This is a big step forward. But we need this in Python to be able to scrape the exact data we want.
We want to convert the exact cURL call into a Python requests call.
Luckily there is a tool to do that here.
We just have to paste the curl request string there, and the tool gives us a Python version ready to go!
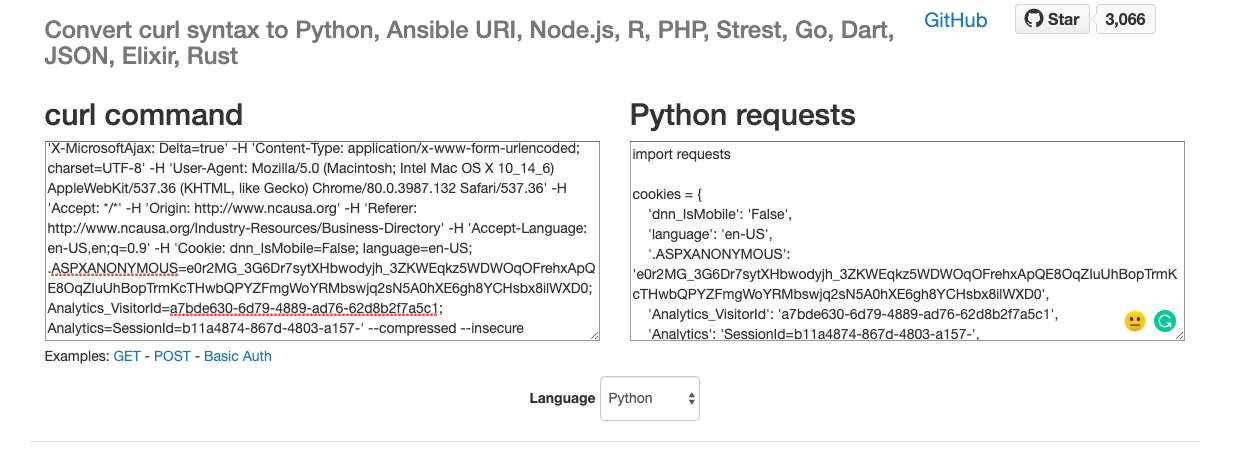
Let's create a python file with this code.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
cookies = {
'dnn_IsMobile': 'False',
'language': 'en-US',
'.ASPXANONYMOUS': 'e0r2MG_3G6Dr7sytXHbwodyjh_3ZKWEqkz5WDWOqOFrehxApQE8OqZIuUhBopTrmKcTHwbQPYZFmgWoYRMbswjq2sN5A0hXE6gh8YCHsbx8ilWXD0',
'Analytics_VisitorId': 'a7bde630-6d79-4889-ad76-62d8b2f7a5c1',
'Analytics': 'SessionId=b11a4874-867d-4803-a157-',
}
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'no-cache',
'X-Requested-With': 'XMLHttpRequest',
'X-MicrosoftAjax': 'Delta=true',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Accept': '*/*',
'Origin': 'http://www.ncausa.org',
'Referer': 'http://www.ncausa.org/Industry-Resources/Business-Directory',
'Accept-Language': 'en-US,en;q=0.9',
}
response = requests.get('http://www.ncausa.org/Industry-Resources/Business-Directory', headers=headers, cookies=cookies, verify=False)
soup=BeautifulSoup(response.content,'lxml')We have also added the Beautiful Soup library to help us scrape the data.
Let's go back to the Chrome Inspector and see what patterns the data has.
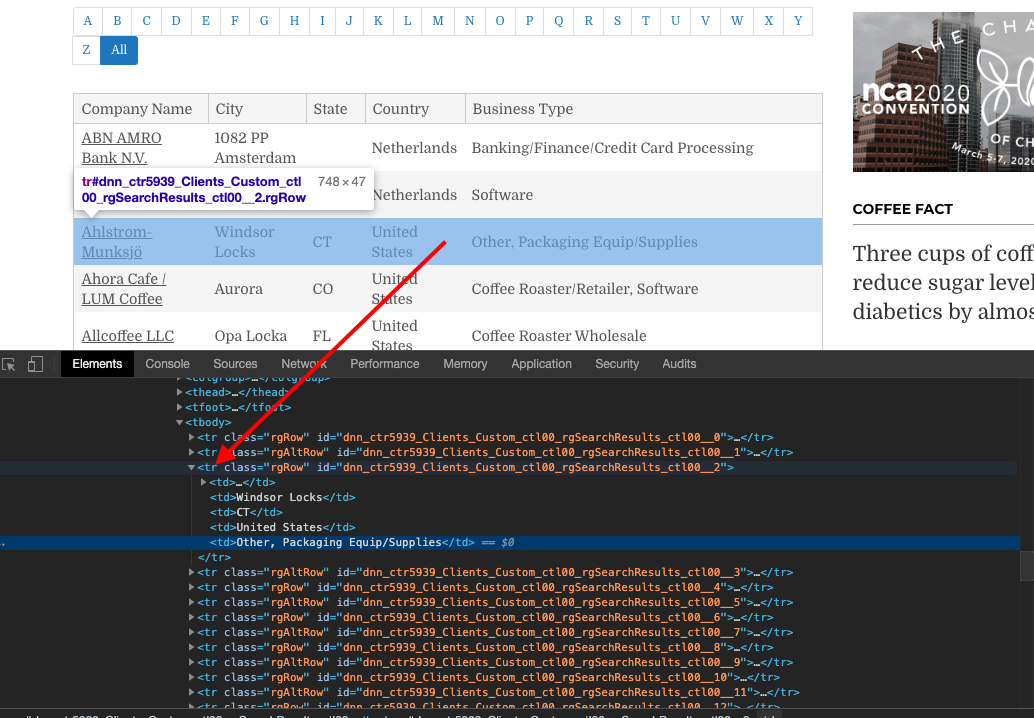
You can see that it is a simple Table with each row containing business and the fields containing the individual fields.
We can open a loop of elements and the loop through the elements simply like this.
for item in soup.select('.rgMasterTable tr'):
try:
print('----------------------------------------')
#print(item)
for columns in item.select('td'):
print(columns.get_text().strip())
except Exception as e:
#raise e
print('')
Putting it all together/.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
cookies = {
'dnn_IsMobile': 'False',
'language': 'en-US',
'.ASPXANONYMOUS': 'e0r2MG_3G6Dr7sytXHbwodyjh_3ZKWEqkz5WDWOqOFrehxApQE8OqZIuUhBopTrmKcTHwbQPYZFmgWoYRMbswjq2sN5A0hXE6gh8YCHsbx8ilWXD0',
'Analytics_VisitorId': 'a7bde630-6d79-4889-ad76-62d8b2f7a5c1',
'Analytics': 'SessionId=b11a4874-867d-4803-a157-',
}
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'no-cache',
'X-Requested-With': 'XMLHttpRequest',
'X-MicrosoftAjax': 'Delta=true',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Accept': '*/*',
'Origin': 'http://www.ncausa.org',
'Referer': 'http://www.ncausa.org/Industry-Resources/Business-Directory',
'Accept-Language': 'en-US,en;q=0.9',
}
response = requests.get('http://www.ncausa.org/Industry-Resources/Business-Directory', headers=headers, cookies=cookies, verify=False)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.rgMasterTable tr'):
try:
print('----------------------------------------')
#print(item)
for columns in item.select('td'):
print(columns.get_text().strip())
except Exception as e:
#raise e
print('')
That's, a devastatingly good looking piece of code and we, went through several hoops to get here.
Saving it as scrapeNCS.py, we run it.
python3 scrapeNCA.pyAnd the results amaze all and sundry.
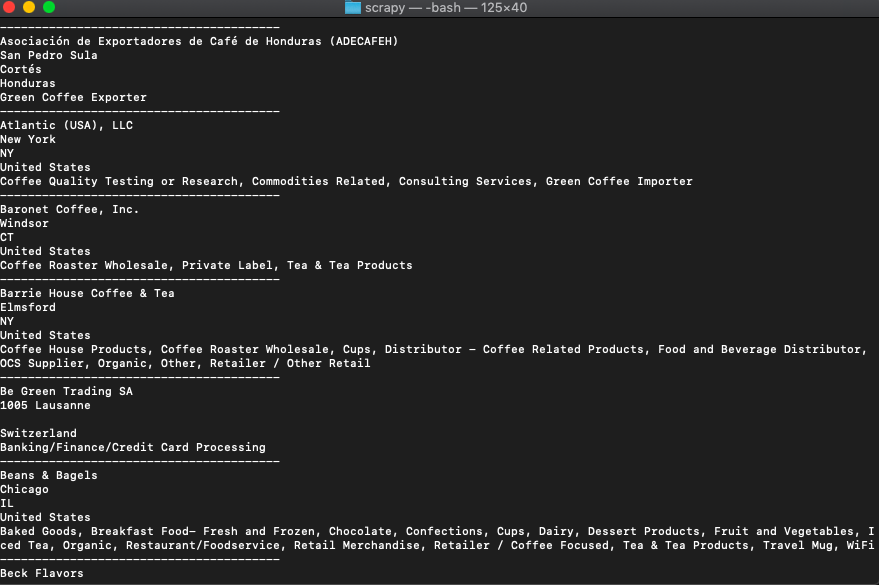
You can now push each of those values into variables and store them in a file or a database.
If you want to use this in production and want to scale to thousands of requests, then you will find that you will get IP blocked easily by many websites. In this scenario, using a rotating proxy service to rotate IPs is almost a must. You can use a service like Proxies API to route your calls through a pool of millions of residential proxies.
If you want to scale the crawling speed and dont want to set up you own infrastructure, you can use our Cloud base crawler crawltohell.com to easily crawl thousands of URLs at high speed from our network of crawlers.