A large part of web crawling is pretending to be human. Humans use web browsers like Chrome and Firefox to browse websites so a large part of web crawling is pretending to be a browser.
User-Agent String
Most websites NEED you to pass a user-agent string they can recognize. User-Agent strings were originally used to customize the responses of the web servers based on the recipient's OS and browser and its version. All this info is passed in a User-Agent string. Here is a typical one...
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36Now, websites use this to restrict or block web crawlers if they see something they dont recognize.
While a lot of developers make sure they set a user-agent string and even rotate them from a list, they dont realize that websites use other typical headers to restrict your web crawler.
Take a look at this typical Chrome request for the home page of Reddit.
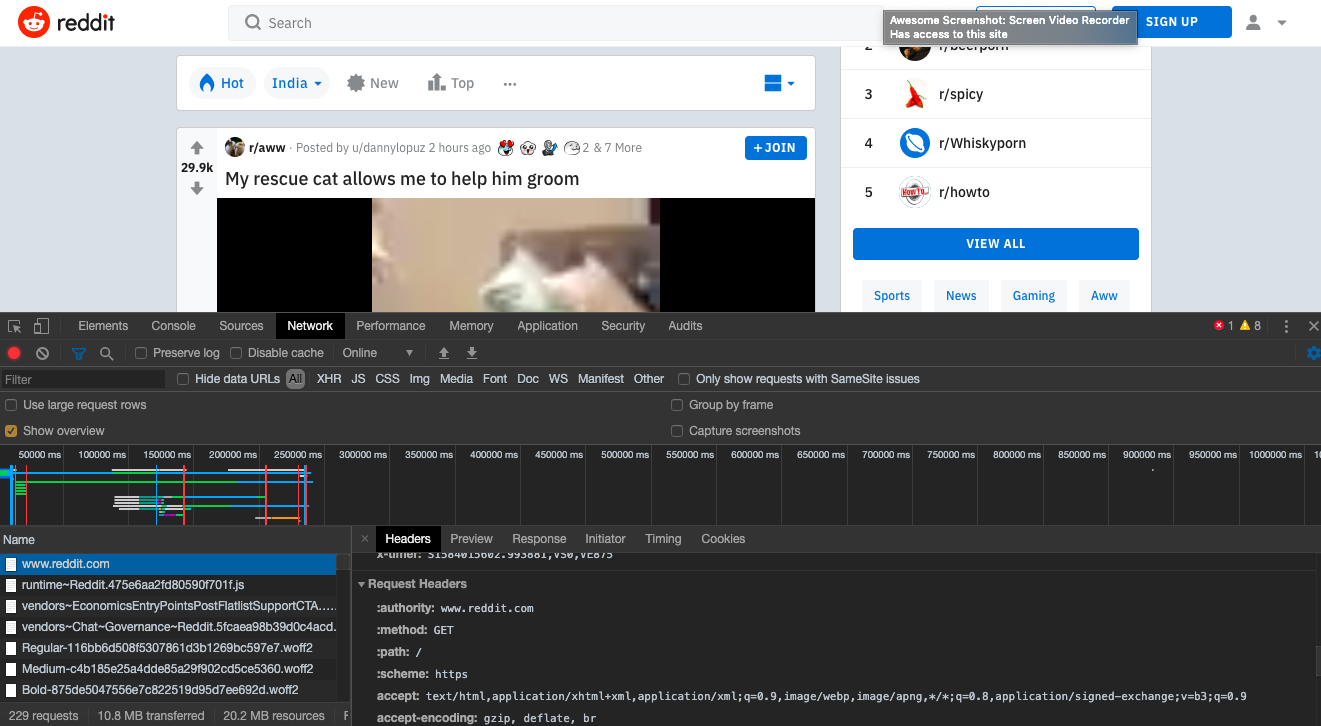
Accept Header
text/html,application/xhtml xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9A clever crawler blocking algorithm might take measures to know that the typical Accept request headers look like the above for the Chrome config.
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36Best to replicate this in your web crawler.
Accept-Encoding
Even though the return format is HTML, web servers want to send you a compressed file to save time and expect all modern browsers to have this request in their headers.
gzip, deflate, brAccept-Language
It's weird when the web browsers don't publish the language that is set up on the machine. A typical request is something like:
en-US,en;q=0.9Referer
Even though strictly speaking, I wen to the Reddit page by directly typing the request in the browser, it's not normal to type in an entire address of a post URL on Reddit. If there are no referees in the HTTP headers, it might be enough grounds t get your crawler blocked.
There you have it. This will help you write web crawlers that dont get blocked easily. But all of these methods cannot hide the IP address. For this you might want to use a rotating proxy service like Proxies API. or if you want to use a completely hands-free crawling option, you can use a service like teracrawler.io both our services.